 |
The SKIRT project
advanced radiative transfer for astrophysics
|
|
The SKIRT project
advanced radiative transfer for astrophysics
|
The SMILE subproject implements the mechanisms for handling SKIRT parameter files in SKIRT and MakeUp. The code in this subproject is designed as a generic framework that can be used ouside of the SKIRT project as well.
The SMILE acronym stands for "Simple Metadata Interactive Language Editing". SMILE is a metadata language that can represent parameter files for software programs or other simple datasets; see The SMILE metadata language below for more information.
The SMILE project supports the SMILE metadata language. It includes utilities for creating and editing SMILE datasets, and a C++ library that can be used by software programs outside of the SMILE project called clients. The overall project structure is illustrated in the following diagram. The arrows indicate dependencies. The components inside the dashed line are part of the SMILE project.

At the center of the project is the SMILE C++ library that offers facilities for working with SMILE schema's and datasets. The library allows a SMILE client to establish a direct correspondence between the client's C++ classes and objects and SMILE schema's and datasets on the other hand. Specifically, the discovery services in the SMILE library translate the SMILE metadata provided for each relevant client C++ class to a SMILE schema. Using this schema, the resurrection services in the SMILE library can construct a run-time object hierarchy reflecting any SMILE dataset conforming to the schema. This happens in a fully type-safe manner, using standard C++ functionality.
The SMILE C++ library is organized in three layers with strict unidirectional dependencies:
The smiletool command-line utility offers a text-based question and answer session for creating a SMILE dataset of any particular type, given a SMILE schema. Just as the SMILE C++ library, this tool is written in standard C++ so that it is very portable. The MakeUp desktop utility offers an even more user-friendly, wizard-style, graphical user interface for creating and editing SMILE datasets of any particular type, again given the corresponding SMILE schema. This utility relies on (and thus requires installation of) the open source Qt GUI framework (https://www.qt.io).
Because all information about the make-up of a SMILE dataset is defined in the corresponding SMILE schema, the operation of the smiletool and MakeUp utilities is fully uncoupled from the operation of any other SMILE clients. For example, a future Web-browser-based utility might very well offer similar SMILE dataset creation and editing. While this would require re-implementing part of the SMILE library using Web-based technologies, it would not affect any of the other components.
There are two fundamentally distinct ways of using the SMILE C++ library. On the one hand, generic utilities such as those shown on the right-hand side of the above diagram (including, e.g., smiletool) can work with any type of SMILE dataset, as long as the corresponding SMILE schema file is available. The items in a SMILE dataset are represented in memory as so-called ghost items that offer generic functionality to store their type and manage their property values. A ghost item has no built-in knowledge about the properties it should support. It instead counts on the schema definition to provide this information.
On the other hand, as shown on the left-hand side of the above diagram, a SMILE client (such as the shapes example program) can implicitly define a SMILE schema through metadata embedded in the Item subclasses of the program. In this case, the client code implements additional functionality that uses the values of the SMILE properties of its classes in some application-specific way. The SMILE library establishes a direct correspondence between the client's C++ classes and a SMILE schema, and between instances of the client's classes and items in a SMILE dataset. Specifically, the discovery services in the SMILE library translate the SMILE metadata provided for each relevant client C++ class to a SMILE schema. Using this schema, the resurrection services in the SMILE library can construct a run-time object hierarchy reflecting any SMILE dataset conforming to the schema.
The SKIRT program, for which the SMILE project was conceived, offers a typical use case. SKIRT defines a large set of C++ classes implementing its simulation capabilities. A particular SKIRT simulation can be configured by constructing an aggregation of instances of these classes at run time, and setting their property values. The simulation is then executed by the code in the various classes, fully depending on the configured run-time structure and property values. SKIRT uses the SMILE library to save a SMILE schema reflecting its simulation class hierarchy. This schema can then be loaded into one of the independent, generic SMILE utilities for creating or editing a SMILE data set acting as a parameter file for SKIRT. Subsequently, SKIRT uses the SMILE library to construct a run-time object hierarchy (instantiating the SKIRT client classes) mirroring the parameter file, and which is used to perform the requested simulation. As an alternative for the user who doesn't have access to the seperate SMILE dataset editing utilities, SKIRT uses the SMILE library to implement a built-in console query and answer session.
Another use case is a program that requires a simple settings file, without a tight coupling between the structure of the settings file and the internal class hierarchy. In this case, the program developer "manually" creates a SMILE schema for the dataset (a SMILE schema for SMILE schema's is provided with the SMILE project for this purpose). A user can then create or edit a settings file using one of the generic SMILE utilities. The program can use the facilities of the SMILE library to load the settings file and access its contents from the ghost items representing the SMILE dataset in memory.
SMILE is a metadata language that can represent simple datasets such as property lists or parameter files for software programs. A SMILE dataset can be stored as a text file using a subset of the standard XML format, which makes it easy to create, modify and use electronically. In addition, the SMILE XML format is fairly accessable for direct viewing and editing by a moderately advanced user.
While SMILE uses a limited subset of the XML standard, it supports complicated data structures including:
The data structure of a particular type of SMILE files is defined by a SMILE schema, which is in turn a SMILE file (with its own schema - a nice recursion!). This allows software tools to validate the proper construction of a SMILE file. Equally important, a software tool can guide a user to create or edit a SMILE file that conforms to a given SMILE schema, without any information other than the schema.
The following diagram shows the structure of a SMILE schema. A connection starting with a diamond represents aggregation, i.e. it means "A uses one or more B's". A connection starting with a triangle represents inheritance, i.e. it means "A is a base for B".
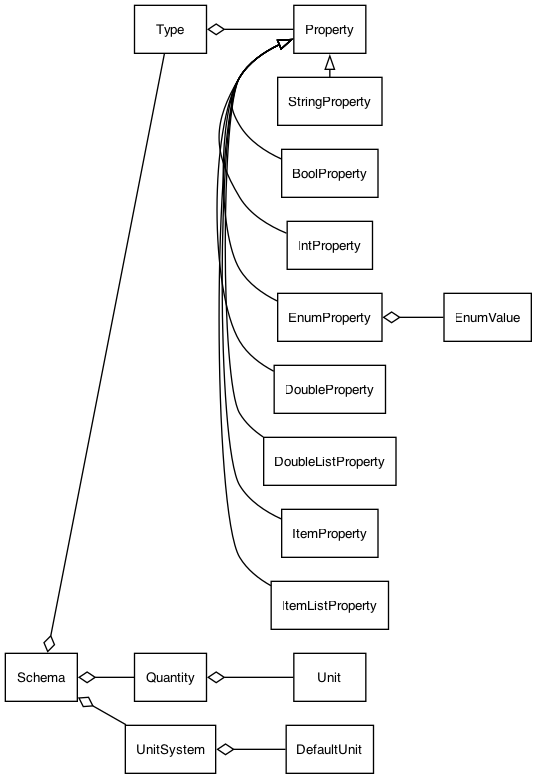
The following tables present the properties for each Smile schema item.
Schema item: Schema – represents a complete Smile schema describing the structure of a dataset
| Property | Type | Description |
| name | string | a short name for this schema; currently not used in a formal way |
| title | string | a longer name for the dataset described by this schema |
| version | string | the version of this schema definition |
| extension | string | the filename extension for datasets described by this schema |
| root | string | the name of the root element in datasets described by this schema |
| type | string | the type of the top-level item in datasets described by this schema, which corresponds to the value of the type attribute on the root element |
| format | string | the version of the described data format, which corresponds to the value of the format attribute on the root element |
| url | string | an optional URL pointing to information on the Web for the schema |
| types | list of Type | a list of schema items representing all types for the described dataset, including concrete types (that can actually occur in the dataset) and abstract types (intermediate types in the inheritance hierarchy); concrete types should be listed in the order in which they should be shown to the user, for example when offering a choice between all subtypes of some base type |
| quantities | list of Quantity | a list of schema items describing physical quantities and the corresponding units used for representing values in the described dataset |
| unitSystems | list of UnitSystem | a list of schema items each describing a unit system and the corresponding default units for each physical quantity |
Schema item: Type – represents a concrete or abstract (compound) item type that may occur in the described dataset
| Property | Type | Description |
| name | string | the name of this type in the described dataset, corresponding to the name of the XML element representing an item of this type in the described dataset |
| title | string | a description of this type for display to a user |
| base | string | the name of the type from which this type directly inherits; if missing or empty this type is a root type |
| concrete | bool | true for concrete types (that can actually occur in the dataset), false for non-concrete types |
| allowedIf | string | a Boolean expression that indicates whether items of the type are allowed; an empty string means always allowed; the attribute values for all direct and indirect base types of this type are ANDed with this value |
| displayedIf | string | a Boolean expression that indicates whether the type is displayed; an empty string means always displayed; the attribute values for all direct and indirect base types of this type are ANDed with this value |
| insert | string | a conditional value expression providing a list of extra names to be inserted in the global and/or local name set when an item of this type is added to the dataset, in addition to the names of the type and its ancestors; an empty string means that no extra names will be added |
| subPropertyIndex | bool | the index in the property list where properties of subtypes should be listed; if nonnegative, properties of subtypes must be listed just before the property with the given index; if negative, properties of subtypes must be listed after the properties of the base type |
| properties | list of Property | a list of schema items describing the properties being encapsulated by this type; the list can contain any of the concrete schema types that inherit from the Property schema item; the properties for all direct and indirect base types of this type are taken into account as well |
Schema item: Property – represents a property that may occur in the described dataset (abstract base for all concrete Property schema items)
| Property | Type | Description |
| name | string | the name of this property in the described dataset, corresponding to the name of the XML attribute (for non-compound properties) or element (for compound properties) representing this property in the described dataset |
| title | string | a description of this property for display to a user |
| relevantIf | string | a Boolean expression indicating whether this property is relevant; an empty string means always relevant |
| displayedIf | string | a Boolean expression indicating whether this property is displayed; an empty string means always displayed |
| requiredIf | string | a Boolean expression indicating whether this property is required; an empty string means always required |
| insert | string | a conditional value expression providing a list of extra names to be inserted in the global and/or local name set when a value of this item is entered into the dataset, in addition to the name automatically associated with the property; an empty string means that no extra names will be added |
| default | string | a conditional value expression providing a default value for the property in case the property is missing string in a format compatible with the particular concrete property type; for compound properties the value indicates the name of a type; an empty string means there is no default value |
Schema item: StringProperty – represents a scalar, non-compound property with an unformatted Unicode string value
| Property | Type | Description |
| ... | ... | properties inherited from Property schema item |
Schema item: BoolProperty – represents a scalar, non-compound property with a Boolean value
| Property | Type | Description |
| ... | ... | properties inherited from Property schema item |
Schema item: IntProperty – represents a scalar, non-compound property with an integer value \(\in[-2\times 10^9,2\times 10^9]\)
| Property | Type | Description |
| ... | ... | properties inherited from Property schema item |
| min | int | the minimum value for the property; if missing the minimum value defaults to \(-2\times 10^9\) |
| max | int | the maximum value for the property; if missing the maximum value defaults to \(2\times 10^9\) |
Schema item: EnumProperty – represents a scalar, non-compound property with a value in a predefined enumerated range
| Property | Type | Description |
| ... | ... | properties inherited from Property schema item |
| enumValues | list of EnumValue | a list of schema items representing the values in the enumeration range for the property |
Schema item: EnumValue – represents one of the values in a predefined enumerated range
| Property | Type | Description |
| name | string | a string representing this enumeration value |
| title | string | a description of this enumeration value for display to a user |
Schema item: DoubleProperty – represents a scalar, non-compound property with as value a floating point number that can be stored in a 64-bit double, plus an optional unit in which the value is to be interpreted
| Property | Type | Description |
| ... | ... | properties inherited from Property schema item |
| min | double | the minimum value for the property; a leading "]" indicates that the specified value is excluded from the allowed range; if missing the minimum value defaults to negative infinity |
| max | double | the maximum value for the property; a trailing "[" indicates that the specified value is excluded from the allowed range; if missing the maximum value defaults to positive infinity |
| quantity | string | the name of the physical quantity this property represents; this must match the name of one of the Quantity schema items in this schema and determines the allowed and default units for the value; if missing the value is dimensionless; also see notes below |
Schema item: DoubleListProperty – represents a non-compound property with as value a list of floating point numbers, with for each value an optional unit in which the value is to be interpreted
| Property | Type | Description |
| ... | ... | properties inherited from Property schema item |
| min | double | the minimum value for each number in the list; a leading "]" indicates that the specified value is excluded from the allowed range; if missing the minimum value defaults to negative infinity |
| max | double | the maximum value for each number in the list; a trailing "[" indicates that the specified value is excluded from the allowed range; if missing the maximum value defaults to positive infinity |
| quantity | string | the name of the physical quantity each number in the list represents; this must match the name of one of the Quantity schema items in this schema and determines the allowed and default units for the values; if missing the values are dimensionless; also see notes below |
Schema item: ItemProperty – represents a compound property with as value an instance of a predefined type or of one of the types inheriting from it
| Property | Type | Description |
| ... | ... | properties inherited from Property schema item |
| base | string | the name of a concrete or abstract type described in this schema; the actual property value can be an instance of any concrete type equal to or inheriting from the specified type |
Schema item: ItemListProperty – represents a compound property with as value a list of instances of a predefined type or of one of the types inheriting from it
| Property | Type | Description |
| ... | ... | properties inherited from Property schema item |
| base | string | the name of a concrete or abstract type described in this schema; the actual items in the list can be instances of any concrete type equal to or inheriting from the specified type |
Schema item: Quantity – represents a physical quantity and the units that can be used to express values for it
| Property | Type | Description |
| name | string | the name of this physical quantity, which can be referenced by the quantity field in property definitions of type double and list of doubles |
| title | string | a description of this physical quantity for display to a user |
| units | list of Unit | a list of schema items of type Unit, describing the units that can be used to express values for this physical quantity |
Schema item: Unit – represents a unit used to express values for a physical quantity
| Property | Type | Description |
| name | string | the name of this unit, which can be referenced by a field of type double in the described dataset to express values for the corresponding physical quantity |
| title | string | a description of this physical quantity for display to a user |
| factor | dimensionless double | the multiplication factor \(f\) used to convert a value given in this unit to internal units according to \(v_\mathrm{program} = f\,v^p + o\); if missing the factor defaults to unity |
| power | dimensionless double | the power index \(p\) used to convert a value given in this unit to internal units according to \(v_\mathrm{program} = f\,v^p + o\); if missing the power index defaults to unity |
| offset | dimensionless double | the offset \(o\) used to convert a value given in this unit to internal units according to \(v_\mathrm{program} = f\,v^p + o\); if missing the offset defaults to zero |
Schema item: UnitSystem – represents a unit system providing a default unit for each physical quantity
| Property | Type | Description |
| name | string | the name of this unit system, which can be referenced from elsewhere in the schema or the described dataset to provide the link discussed in the note below |
| title | string | a description of this unit system for display to a user |
| defaultUnits | list of DefaultUnit | a list of schema items of type DefaultUnit, each defining the default unit under this unit system for a physical quantity described in this schema |
Schema item: DefaultUnit – defines the default unit for a physical quantity
| Property | Type | Description |
| quantity | string | the name of the physical quantity for which this item defines the default unit; the quantity must be properly defined in this schema |
| unit | string | the name of the unit that serves as a default for the physical quantity referenced by this item; the unit must be listed in the quantity definition |
Objectives
The SMILE schema language supports dynamically adjusting default values and displaying or hiding options based on choices made earlier in the configuration process. These earlier choices may represent various aspects of the configuration; for example, in case of the SKIRT client:
All the metadata needed to control these capabilities is defined in the SMILE schema, and thus in case of a client such as SKIRT, in the SMILE metadata declared with each class.
Names and namespaces
In this discussion, we assume that the engine driving the SMILE configuration user interface scans the type and property hierarchy of the SMILE schema in a sequential manner, allowing only forward navigation. If the engine allows the user to navigate backwards (or even randomly), it must emulate the sequential behavior for the purposes of the capabilities discussed here.
The engine maintains two sets of names with a different scope. The global set contains names that stay around for the duration of the configuration session. The local set contains names that stay around only while configuring the properties of a particular type; a fresh local set is created for each type instance. By definition, the global set contains names that start with an uppercase letter, and the local set contains names that start with a lowercase letter. As a result, the two sets form disjoint namespaces. After the first character (which must be a letter), a name can include any mix of letters and digits (and no other characters). Names are never removed from a set (although the local set is regularly discarded and replaced by a new one as a whole). Names are inserted in each of the sets as follows:
| Property type | Insert what | If and only if |
|---|---|---|
| Int | property name | numeric value is nonzero |
| Double | property name | numeric value is nonzero |
| Bool | property name | Boolean value is true |
| String | property name | string contents is not empty |
| Item | property name | item is present (i.e. not null) |
| DoubleList | property name | double list is not empty |
| ItemList | property name | item list is not empty |
| Enum | Property name + enumeration value | always |
In addition, the "insert" type or property attribute may cause one or more names given in the attribute value to be inserted whenever the value of the corresponding property or type is being configured. In that case, each name is inserted in the global or local set depending on the capitalization of the first letter in the name.
Boolean expressions
Some type or property attributes accept an arbitrary Boolean expression that will be evaluated to true or false whenever the value is required. The expression is formed by combining identifiers (consisting of letters and digits) in the usual way with the unary negation operator #!, the binary OR operator #|, the binary AND operator #&, and (balanced) parenthesis. In the absence of parenthesis, the negation operator has the highest precedence; otherwise operations are executed from left to right.
When evaluating the expression, identifiers that correspond to a name currently in the global or local set are replaced by the Boolean value true; other identifiers are replaced by false.
Conditional value expressions
Some type or property attributes accept a conditional value expression that will be evaluated to one of the specified values whenever the value is required. The syntax of a conditional value expression can be illustrated as follows:
<Boolean-expression1>:<value1>; ... ;[<Boolean-expressionN>:]<valueN>
In other words, there is a sequence of one or more condition-value pairs separated by a semicolon, while the condition and the value are separated by a colon. In the last pair of the sequence, the condition (including the colon) may be missing; if so it defaults to “true”.
Note that this syntax precludes the values to contain colons and semicolons. This is no problem for numerical values or for type names, and even for string values it will most likely not be a significant limitation.
The pairs in the conditional value expression are considered from left to right. When the condition for a pair evaluates to true (using the Boolean expression rules explained above), the corresponding value represents the value of the complete expression and further evaluation is terminated.
Attributes
The following table lists the type and property attributes that support conditional values:
| Attribute | Value type | Default | Available for |
|---|---|---|---|
| allowedIf | Boolean expression | true | type |
| relevantIf | Boolean expression | true | property |
| displayedIf | Boolean expression | true | type, property |
| requiredIf | Boolean expression | true | property |
| default | conditional value expression | - | property |
| insert | conditional value expression | - | type, property |
A type is listed as part of the choices for an item property if both its allowedIf and displayedIf attributes evaluate to true. The difference between these attributes for a type lie only in the reason for the omission of the type: in the first case, including the type would create an invalid configuration, in the second case, the user does not have the expertise to deal with the type.
A property is displayed as part of the configuration for a given type instance if both its relevantIf and displayedIf attributes evaluate to true. The difference between these attributes for a property is similar to that for types: in the first case, the value of the property will not be used in the current configuration, in the second case, the user does not have the expertise to deal with the property. This semantic difference has some intricate consequences. For example, the engine must be able to derive a meaningful value for a relevant property, even if it is not displayed. Thus, such a property must either be optional (i.e., not required) or have a default value.
Supporting a conditional value expression for the default attribute enables providing a different default value depending on the configuration so far.
The value of the conditional value expression in the insert attribute can be a single name or a list of names separated by commas. The names are inserted in the global or local set depending on their first letter, as described before. The insert attribute facilitates managing complex dependencies in the configuration.
The smiletool command-line utility offers a text-based question and answer session for creating a SMILE dataset of a particular type, according to one of the SMILE schema files residing in a schema library directory. Such a session can be started as follows:
smiletool -l <library_dirpath>
The tool can also be used to create a LaTeX representation of a SMILE dataset, as long as the corresponding SMILE schema is in the library. For example:
smiletool -l <library_dirpath> -i <input_dataset_filepath> -t <output_latex_filepath>
In more detail, the smiletool command-line tool supports the following command line arguments; they are all optional and their order is not significant:
smiletool [-i <input_dataset_filepath>]
[-o <output_dataset_filepath>] [-t <output_latex_filepath>]
[-l <library_dirpath>] [-s <schema_filename>]
If an input dataset filepath is present (the -i option), the specified dataset is loaded into memory. Otherwise, an interactive console query and answer session is conducted to create a new dataset in memory.
If an output dataset filepath is present (the -o option), the memory dataset is saved to the specified file. Similarly, if an output latex filepath is present (the -t option), the memory dataset is converted to LaTeX source form and saved to the specified file. In both cases, an appropriate filename extension is added if needed, and an existing file with the final name gets overwritten without warning. The -o and -t options can both be specified at the same time. If neither is specified, the user is prompted for a dataset filename at the console. In this case, an appropriate filename extension is added if needed as well, however the name of an existing file will not be accepted.
To operate the tool in batch, i.e. without console prompting, both an input dataset filepath (the -i option) and at least one output filepath (-o and/or -t options) must be present.
The library directory path (the -l option) specifies the location of SMILE schema files. If this option is missing, the current directory is used instead. The schema file name (the -s option) specifies the schema to be used for interpreting or constructing a dataset. The .schema filename extension is added if needed. The schema file must reside in the library directory. If this option is missing, the appropriate schema is either derived from the input data set (if one is specified), or the user is asked to select a schema from those found in the library directory.
The MakeUp desktop utility offers a user-friendly, wizard-style, graphical user interface for creating and editing SMILE datasets of any particular type, given the corresponding SMILE schema. This utility relies on (and thus requires installation of) the open source Qt GUI framework (https://www.qt.io).
On some systems, MakeUp can be launched by double-clicking its application icon. For example, on Mac OS X, MakeUp is built as an application bundle. However, it can always be launched via the command-line. For example, on Mac OS X:
.../MakeUp.app/Contents/MacOS/MakeUp
When launched for the first time, MakeUp searches for a default SMILE schema library in its immediate vicinity in the file system. However, in any case, the path to the SMILE schema library can be selected through the graphical interface on the initial panel of the wizard:

For each SMILE schema found in the library directory, the initial panel shows two options: one to create and configure a new dataset, and one to open and edit an existing dataset. The user can navigate through the wizard panes by selecting the appropriate choices (or filling in fields) and clicking the "Continue" and "Back" buttons at the bottom. Here is an example wizard pane shown as part of the editing process of a shapes parameter file:

In essence, MakeUp asks the same questions as the smiletool command-line tool using a nicer interface. There are two important additional benefits though:
The fundamentals layer offers low-level capabilities including platform-independent system interaction, basic string handling, and XML processing. The following paragraphs introduce a few selected classes in this layer.
The Basics header file should be included directly or indirectly in all program units for the project to include the headers for some frequently-used standard library facilities in a consistent manner.
The System class provides a set of functions that interact with the operating system or with the file system, often in a platform-dependent manner. One important function of the class is translating internal UTF-8 encoded strings to and from the encoding expected by the host system. A single instance of the System class must be constructed just after program startup.
The Array, Table and ArrayTable classes implement containers that hold sequences of double values with a predictable size (i.e. the array or table size is known at run time when the container is first initialized). The Array class allows easily and efficiently performing mathematical operations on the corresponding values in multiple arrays. The Table and ArrayTable classes offer multi-dimensional table indexing.
The StringUtils class offers facilities for working with std::string objects, including various query and transform functions and conversions to and from numeric data types.
The CommandLineArguments class serves as a basic command line parser. It supports any number of filepath arguments and options with or without a value. Individual filepaths, options, and option values must be separated from each other by whitespace. An option always starts with a dash; a filepath and an option value don't.
The XmlReader and XmlWriter classes implement reading and writing of the XML subset that is sufficient to represent SMILE schemas and datasets. The classes support well-formed XML 1.0 documents with certain additional limitations and caveats, as decribed in the respective class headers.
The schema and discovery layer offers facilities for processing SMILE schema's and representing SMILE datasets in memory, and for performing introspection (or discovery) on C++ classes in SMILE client code.
The Item class is the abstract base class for classes corresponding to the SMILE data types listed in a SMILE schema. In other words, an instance of an Item subclass represents a particular item in a dataset described by a SMILE schema. Ghost items are instances of the GhostItem class (based on Item) defined as part of the SMILE library. A ghost item offers generic functionality to store its type and to manage property values. Client items are instances of Item subclasses defined in client code that uses the SMILE library. These classes define SMILE properties through the macros provided for that purpose in the ItemInfo.hpp header file, and implement additional functionality that uses the values of these properties in some application-specific way. The Item base class offers facilities to help manage a run-time item hierarchy (reflecting the structure of a given SMILE dataset), and to support the discovery mechanisms offered by other parts of the SMILE library.
The ItemRegistry class manages the global registry of client Item subclasses defined in a program. Client Item subclasses must be explicitly registered with the registry at startup.
The SchemaDef class represents a SMILE schema definition. It offers facilities for loading a SMILE schema from file or, through the ItemRegistry, from the discovery metadata published by a set of client Item subclasses. Portions of the schema definition are represented by instances of the TypeDef, PropertyDef, and UnitDef classes. A SchemaDef instance can construct SMILE items (i.e. instances of Item subclasses) given their type (as a string), and can spawn an appropriate property handler (see below) given a target item and a property name (as a string).
The PropertyHandler class and its subclasses handle SMILE data item properties for the purpose of serialization and resurrection. A PropertyHandler subclass instance combines knowledge about the schema definition describing the SMILE dataset being handled, the target data item within that dataset, the target property within that item, and the type of that property. There is a specific PropertyHandler subclass for each supported property type, including string, Boolean, enumeration, integer, floating point and pointer to item types. These latter property types are used to link items into a hierarchy that reflects a given SMILE dataset.
The serialization and resurrection layer uses the capabilities of the other layers to serialize and deserialize SMILE data sets, and to resurrect a client's C++ object hierarchy from a SMILE dataset.
For example, the XmlHierarchyCreator class offers a static function to create a memory representation of a SMILE dataset, given its XML serialization (in a file) and the corresponding schema definition (as a SchemaDef instance). If the schema definition was derived from the metadata published by a set of client Item subclasses in the program, the items in the returned hierarchy will be instances of the appropriate client Item subclasses. If the schema definition was loaded from an XML file, the items in the returned hierarchy will be GhostItem instances.
Conversely, the XmlHierarchyWriter class offers a static function to write the structure and properties of a SMILE dataset representation in memory to an XML file, given the corresponding schema definition (as a SchemaDef instance). The function works for both client and ghost item hierarchies. The generated XML file contains sufficient information to reconstruct a fresh copy of the SMILE dataset (using the XmlHierarchyCreator class).
The other classes in this layer provide similar services. The ConsoleHierarchyCreator class implements a console query and answer session to construct a (client or ghost) memory representation of a SMILE dataset. The LatexHierarchyWriter class outputs a LaTeX representation of a SMILE dataset that can be easily turned into a nicely formatted document using a LaTeX processor.
The shapes command-line program included in the SMILE project serves as an example of the typical SMILE library use case. The program defines a small set of client Item subclasses for representing a collection of two-dimensional shapes and their properties (see ShapeItem and its subclasses). Given an interconnected run-time tree of instances of these classes, the program can render a visualization of the described collection to a pixel image (see the Canvas class). The program uses the ItemInfo.hpp macros to declare discovery metadata for the ShapeItem subclasses and their properties (see, e.g., the ColorDecorator class), and registers these classes with the SMILE item registry (see the ShapeRegistry class). The SMILE schema definition derived from this information describes a SMILE dataset that, in turn, represents a collection of shapes that can be rendered by the program.
The shapes program supports the following command line arguments (see the ShapesCommandLineHandler class):
shapes -x <library_dirpath> shapes <shapes_dataset_filepath> [-o <tiff_output_filepath>]
The first form causes a SMILE schema file to be generated corresponding to the metadata in the source code (i.e. in the class definitions of the Item subclasses). The file is named 'shapes.smile' and is placed in the specified directory. Assuming that this file is placed in the appropriate schema library directory, the smiletool command-line tool and/or the MakeUp desktop utility are now enabled to create and edit shapes parameter files (as shown in the section on The MakeUp desktop utility).
The second form generates a TIFF image based on the instructions provided in the shapes parameter file (a SMILE dataset) specified as the first command line argument. The .shapes filename extension may be included or omitted. If the optional output filepath is present (the -o option), it specifies the path to the image file that will be created according to the instructions in the parameter file. The .tiff filename extension is added unless the filepath already has the .tiff filename extension. If the -o option is not present, the output filepath is derived from the parameter filepath by replacing the .smile filename extension by the .tiff filename extension.
Below is an example shapes parameter file. Because the design goal was to show various SMILE features, the structure of the parameter file is perhaps more complicated than it could have been.
<?xml version="1.0" encoding="UTF-8"?>
<shapes-definition type="ShapeCanvas" format=".." producer=".." time="..">
<ShapeCanvas>
<shape type="Shape">
<ShapeGroup>
<shapes type="Shape">
<RectangleShape x="0.6 m" y="0.2 m" width="0.5 m" height="0.1 m"/>
<ColorDecorator color="Red">
<shape type="Shape">
<RectangleShape x="0.8 m" y="0.7 m" width="0.1 m" height="0.15 m"/>
</shape>
</ColorDecorator>
<WidthDecorator width="0.03">
<shape type="Shape">
<ColorDecorator color="Custom" rgb="0.4, 0.1, 0.9">
<shape type="Shape">
<RectangleShape x="0.3 m" y="0.4 m" width="0.3 m" height="0.1 m"/>
</shape>
</ColorDecorator>
</shape>
</WidthDecorator>
<PolygonShape x="0.25 m" y="0.75 m" radius="0.2 m" numSides="5" align="true"/>
</shapes>
</ShapeGroup>
</shape>
</ShapeCanvas>
</shapes-definition>
And here is the corresponding rendered image:
